defgen(batch_size=32): X = np.zeros((batch_size, height, width, 3), dtype=np.uint8) y = [np.zeros((batch_size, n_class), dtype=np.uint8) for i inrange(n_len)] generator = ImageCaptcha(width=width, height=height) whileTrue: for i inrange(batch_size): random_str = ''.join([random.choice(characters) for j inrange(4)]) X[i] = generator.generate_image(random_str) for j, ch inenumerate(random_str): y[j][i, :] = 0 y[j][i, characters.find(ch)] = 1 yield X, y
上面就是一个可以无限生成数据的例子,我们将使用这个生成器来训练我们的模型。
使用生成器
生成器的使用方法很简单,只需要用 next
函数即可。下面是一个例子,生成32个数据,然后显示第一个数据。当然,在这里我们还对生成的
One-Hot 编码后的数据进行了解码,首先将它转为 numpy
数组,然后取36个字符中最大的数字的位置,因为神经网络会输出36个字符的概率,然后将概率最大的四个字符的编号转换为字符串。
1 2 3 4 5 6 7
defdecode(y): y = np.argmax(np.array(y), axis=2)[:,0] return''.join([characters[x] for x in y])
X, y = next(gen(1)) plt.imshow(X[0]) plt.title(decode(y))
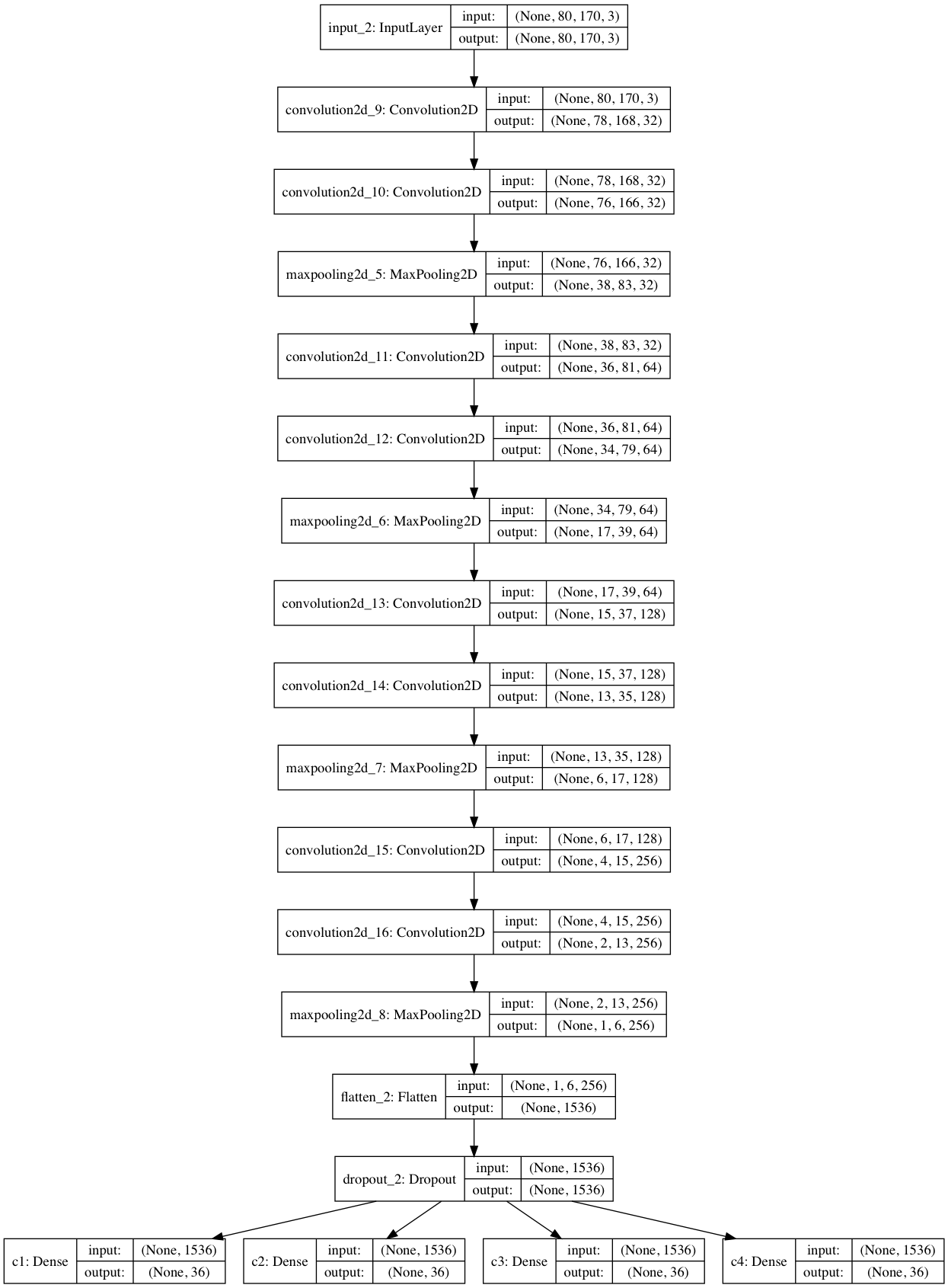
构建深度卷积神经网络
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
from keras.models import * from keras.layers import *
input_tensor = Input((height, width, 3)) x = input_tensor for i inrange(4): x = Convolution2D(32*2**i, 3, 3, activation='relu')(x) x = Convolution2D(32*2**i, 3, 3, activation='relu')(x) x = MaxPooling2D((2, 2))(x)
x = Flatten()(x) x = Dropout(0.25)(x) x = [Dense(n_class, activation='softmax', name='c%d'%(i+1))(x) for i inrange(4)] model = Model(input=input_tensor, output=x)
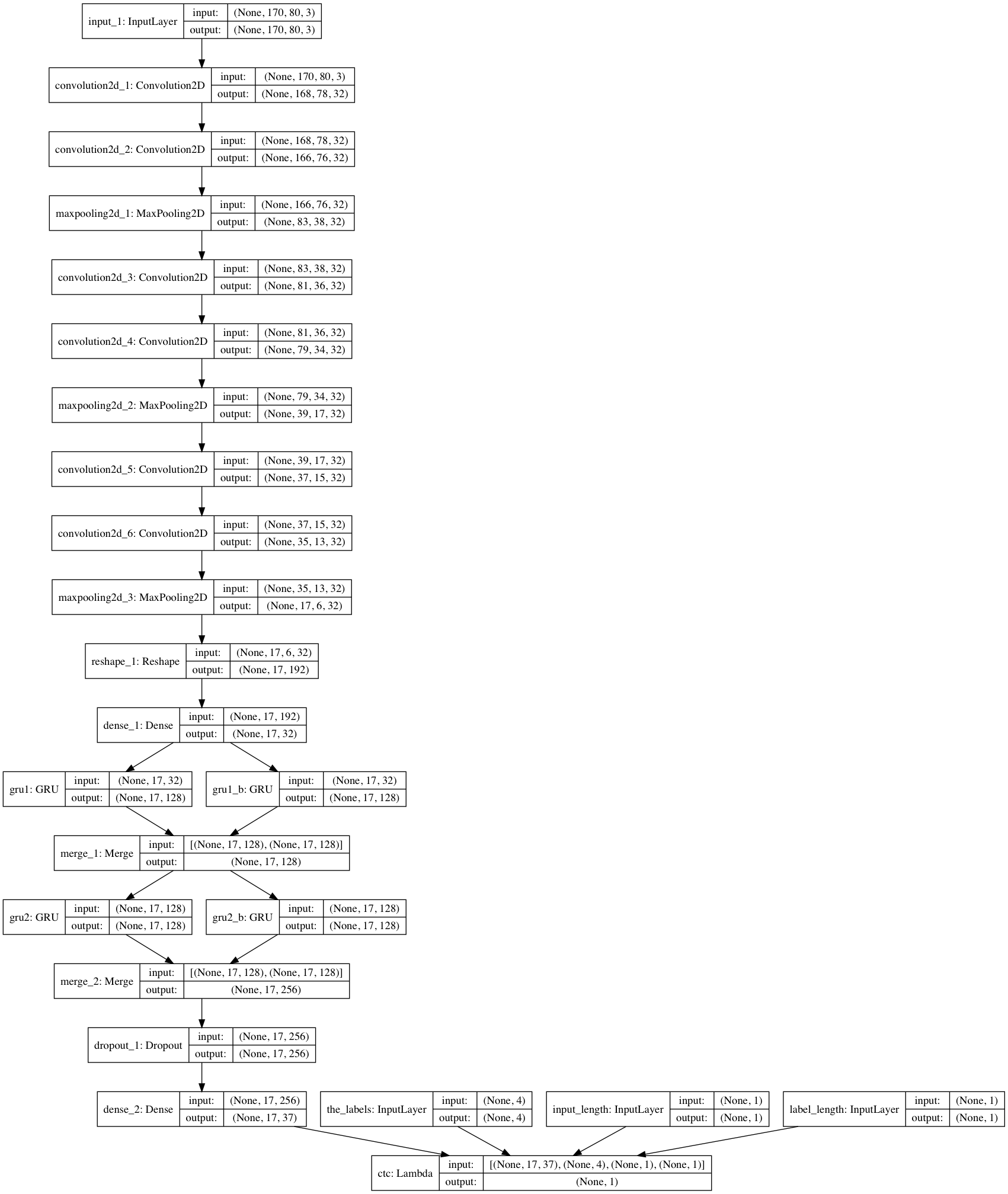
from keras.models import * from keras.layers import * rnn_size = 128
input_tensor = Input((width, height, 3)) x = input_tensor for i inrange(3): x = Convolution2D(32, 3, 3, activation='relu')(x) x = Convolution2D(32, 3, 3, activation='relu')(x) x = MaxPooling2D(pool_size=(2, 2))(x)
conv_shape = x.get_shape() x = Reshape(target_shape=(int(conv_shape[1]), int(conv_shape[2]*conv_shape[3])))(x)
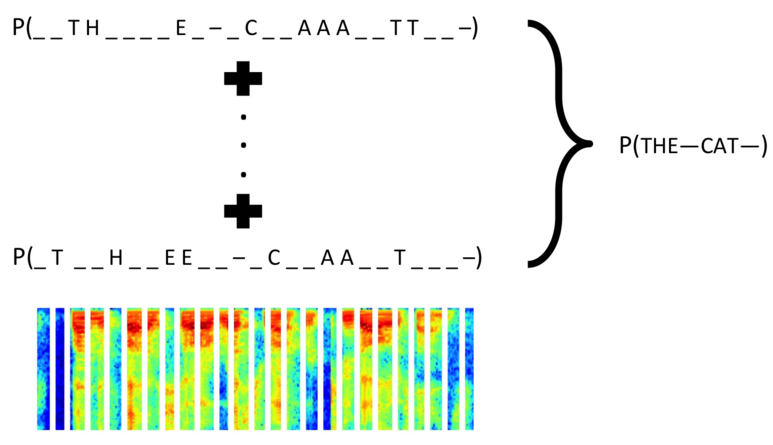
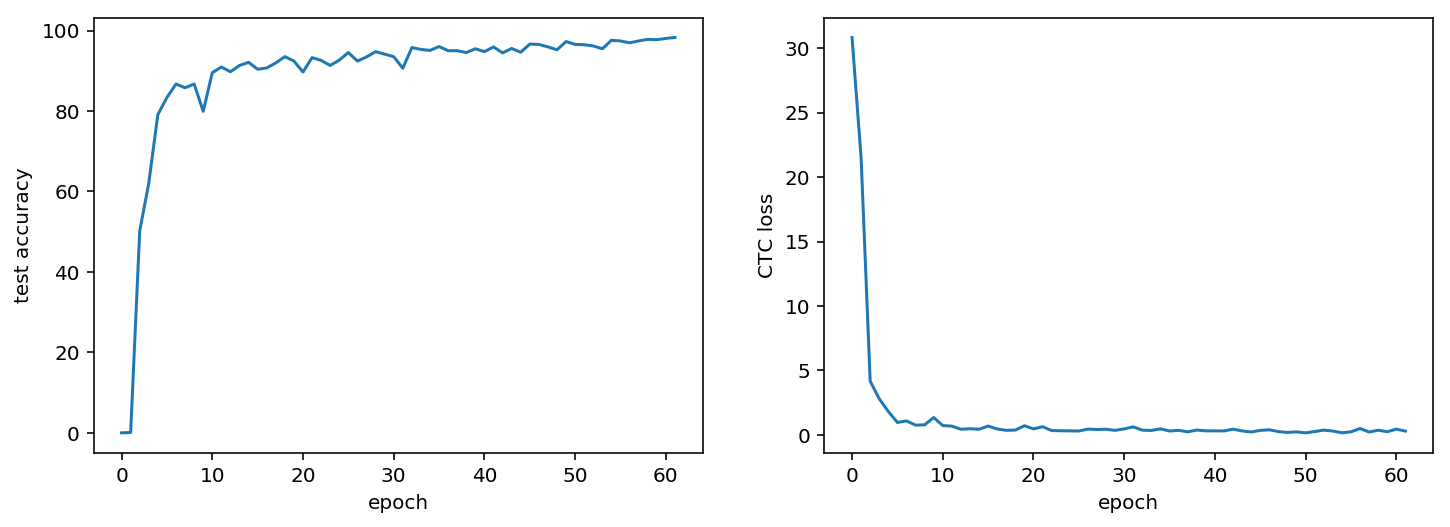
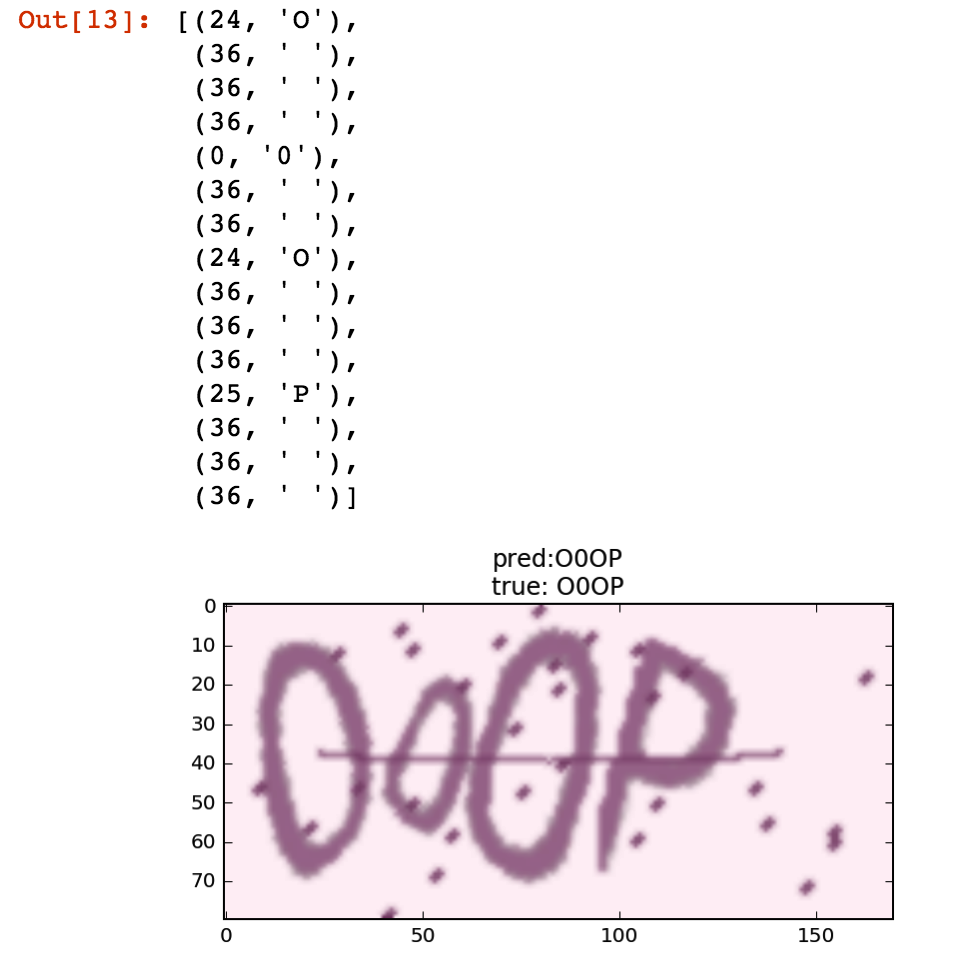
defgen(batch_size=128): X = np.zeros((batch_size, width, height, 3), dtype=np.uint8) y = np.zeros((batch_size, n_len), dtype=np.uint8) whileTrue: generator = ImageCaptcha(width=width, height=height) for i inrange(batch_size): random_str = ''.join([random.choice(characters) for j inrange(4)]) X[i] = np.array(generator.generate_image(random_str)).transpose(1, 0, 2) y[i] = [characters.find(x) for x in random_str] yield [X, y, np.ones(batch_size)*int(conv_shape[1]-2), np.ones(batch_size)*n_len], np.ones(batch_size)
characters2 = characters + ' ' [X_test, y_test, _, _], _ = next(gen(1)) y_pred = base_model.predict(X_test) y_pred = y_pred[:,2:,:] out = K.get_value(K.ctc_decode(y_pred, input_length=np.ones(y_pred.shape[0])*y_pred.shape[1], )[0][0])[:, :4] out = ''.join([characters[x] for x in out[0]]) y_true = ''.join([characters[x] for x in y_test[0]])